KAIST 김재철AI대학원 AI설명회 정리-3

이번 포스팅은 코엑스에서 개최된 2022 AI Expo에서 KAIST 김재철AI대학원 AI기술설명회 세미나 참석하고 간단하게 개인 의견을 포함하여 두서없이 정리한 마지막 포스팅 입니다.
✔️ 설명 가능한 인공지능 동향 [Link]
✔️ 의료 인공지능의 동향 [Link]
✔️ 생성모델 기술 동향 [Link]
✔️ Federated learning
✔️ 자기지도(self-supervised) 기반 비지도 학습 기술
✔️ 가상인간 기술
정리한 내용이 많아 글은 총 3편으로 나누어서 작성하겠습니다.
Federated Learning
Federated Learning(연합 학습)은 서로 다른 환경을 지닌 다수의 디바이스들이 협력하여 하나의 네트워크를 학습하거나 또는 개개인의 성능을 높이는 학습 방법입니다. 이해가 쉽도록 하나의 예시를 들어보겠습니다.
‘A’라는 병원의 데이터로 AI 모델을 학습해서 좋은 성능을 이끌어 냈습니다. 이 모델을 이용해서 ‘B’라는 병원, 혹은 해외의 ‘C’병원에서도 제대로 동작하고 비슷한 성능이 나올 수 있도록 인공지능 모델을 학습하고 싶은 경우가 있습니다. 이런 경우 흔히 생각해볼 수 있는 내용은 'A'데이터를 이용해서 학습한 모델을 fine-tunning을 시키면 되는게 아닌가? 라는 생각을 할 수 있습니다. 이렇게 할 경우 ‘A’데이터 특성을 잃어버리게 되어 옳지 못한 방법이고 오히려 성능이 더 저하될 수 있습니다. 따라서 이런 경우에는 Federated Learning 학습 방법을 이용해서 아래 그림과 같이 여러 디바이스(병원, 스마트폰 등)에서 네트워크를 학습하고 설계를 해야합니다.
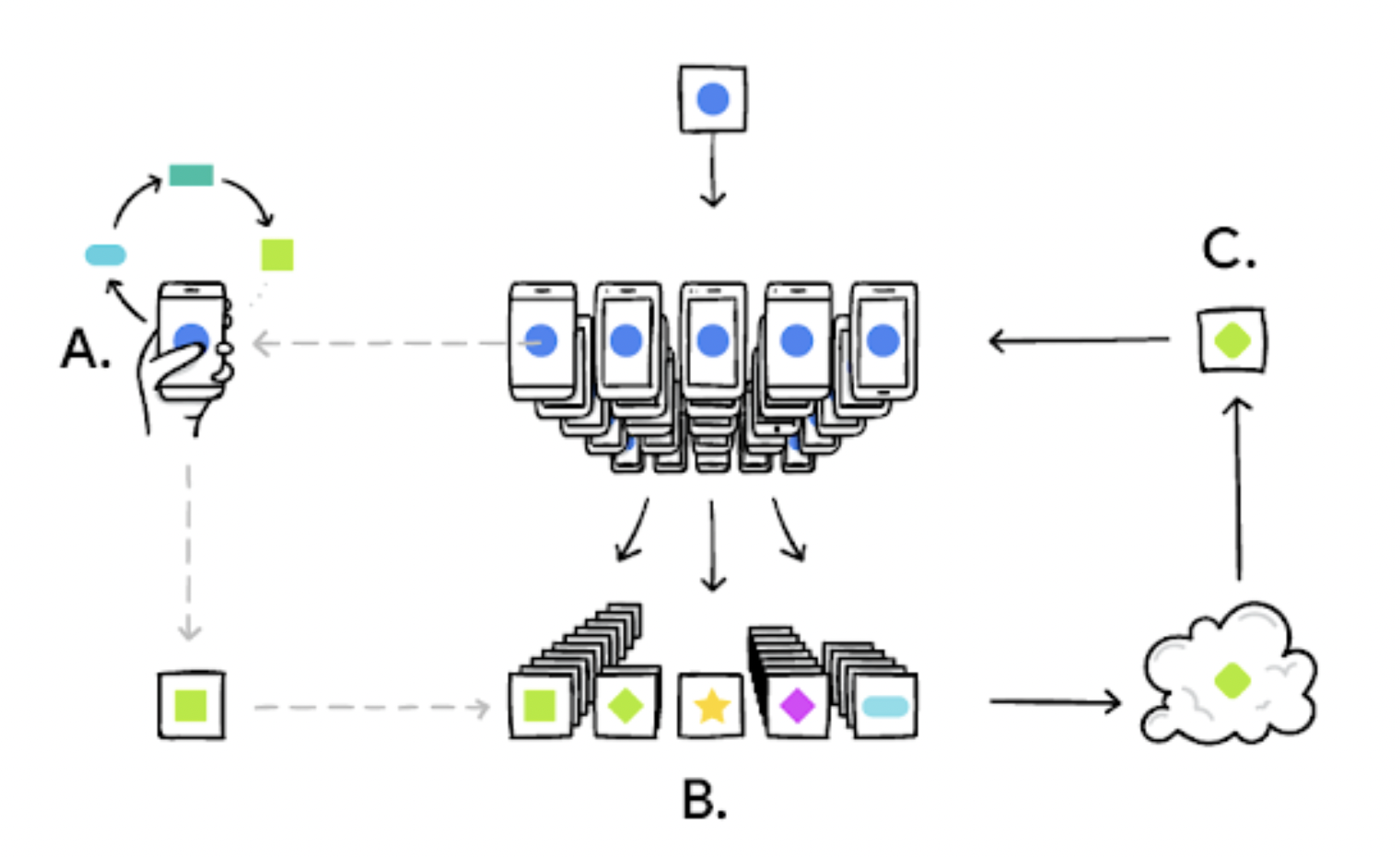
👉 더 자세한 내용: 연합 학습(Federated Learning), 그리고 챌린지
Data Heterogeneity (데이터 이질성)
여러 디바이스들이 협력하여 하나의 네트워크를 학습하기 위해서는 각 디바이스마다 다른 형태와 특성을 지닌 데이터들로 학습해야합니다. 또한 스마트폰 같은 경우 민강한 데이터 정보가 있는 경우가 많아 privacy 문제도 고려해가며 학습을 해야하는 경우가 있습니다. 이런 특성을 Data Heterogeneity 라고 합니다. Data Heterogeneity 특성을 잘 이용해서 스마트 디바이스들마다 local update를 하면 오히려 더 좋은 성능을 얻을 수 있습니다. 이 과정은 좀 더 specific한 decision을 내보내면서 더 좋은 성능을 얻게 됩니다.
KAIST에서는 Global model로 수렴을 시킬 때 좋은 방법과 Data Heterogeneity특성을 최대한 이용해서 성능이 좋아질 수 있는 방법에 대한 연구를 진행하고 그 내용을 소개해주었습니다. 이 내용으로 접근해서 연구한 방법으로는 전체적으로 업데이트를 시키지 않고 구역을 나누어 특정 부분의 layer만 업데이트하는 방법 입니다. Neural network는 여러개의 layer로 이루어진 선형모델 입니다. 이를 깊게 쌓을수록 많은 연상량과 파라메터 갯수가 많아지고 우리는 이를 딥러닝 모델이라고 부릅니다. 이런 딥러닝 모델을 학습할때는 global 하게 모든 layer를 동시에 업데이트 하게 됩니다. 이런 방법은 전혀 다른 데이터가 들어올 때 좋은 성능을 얻을 수 없게 됩니다. 하지만 네트워크 구역을 나누어서 특정 부분의 layer만 업데이트하여 학습을 진행하는 방법이 FedBABU라는 논문의 방법이며 이에 대한 내용은 아래에서 알아보도록 하겠습니다.
FedBABU
📄paper: FedBABU: Towards Enhanced Representation for Federated Image Classification
Federated Learning은 모든 사용자에게 적절하게 작동하는 모델과 각 개인에게 미리 맞춤화된 모델 두가지 방향성을 지니고 있습니다. 하지만 Google에서 발표한 FedAvg: Federated Averaging에서 global하게 잘 되는 모델은 local device에서는 더이상 성능 향상이 어렵다는 문제가 발생하게 됩니다. 그 이유는 classifier를 각자 다르게 학습해서 문제가 발생하는 것 입니다. 그래서 FedBABU 논문에서 제안하는 방법은 classifier는 update 안되도록 고정시키고 random weight를 지내도록 설정을 한 후 classifier를 제외한 나머지 부분만 weight update 되도록 학습합니다. 이 방법은 각 사용자마다 classifier 전까지만 학습시켜 실제적으로 representation만 바꾸게 됩니다. 이와 비슷한 연구로 Representation learning 연구 분야로 ICLR 2021에서 소개된 BOIL논문이 있습니다. 이 논문은 FedBABU와는 다르게 outer loop에서 classifier는 update를 하지만 FedBABU에서는 거의 고정된다는 부분이 다릅니다.
구역을 나누었을 때 장점
classifier는 고정하고 나머지 부분만 update하는 경우의 장점은 사용자들이 서로 다른 data구성을 가지는 상황에서 representation을 학습하는 것이 제각각이 될 위험이 있는데 FedBABU에서 제안한 방법대로 classifier는 random하게 두고 나머지 부분만 update되도록 학습하면 고정된 기준점을 가지고 학습하는 것이기 때문에 좀 더 효과적으로 학습할 수 있게 됩니다.
이런 식으로 구역을 나누어서, global, local로 업데이트를 따로 진행을 하다 보면 Federated learning 차원에서 좋은 성능을 얻을 수 있습니다. 또한 Knowledge Distillation를 잘 활용하면 더 좋은 성능을 얻을 수 있다고도 설명을 해주셨습니다.

자기지도(self-supervised) 기반 비지도 학습 기술
self-supervised learning이 활용되는 이유는 딥러닝 모델 학습 과정 중 아래와 같은 문제점들을 해결하기 위한 방법입니다.
딥러닝 학습할 대 별로의 라벨(label) 데이터 필요
지도 학습(supervised learning)으로 학습할 때 학습 데이터와 라벨 데이터가 필요합니다. 이를 위해선 라벨링 과정이 필수적으로 필요하지만 이런 과정은 많은 시간과 비용이 들게 되며 특히 전문성을 요구하는 도메인의 데이터들은 더더욱 많은 제약조건이 요구됩니다.
레이블이 없는 데이터 수집은 쉽다
레이블이 필요 없는 데이터는 그냥 데이터 수집만 하면 되니까 비교적 시간과 비용이 덜 들게 됩니다.
위 두가지 문제점을 볼 때 비지도 학습 방법론의 중요성과 필요성을 볼 수 있으며 그 중에 self-supervised learning에 대한 연구 방법론을 설명해주셨습니다.
self-supervised 학습 방법
정답 라벨(lable) 없이 입력 데이터만 이용하여 모델 학습하는 방법으로 입력 데이터만을 이용해서 라벨을 생성합니다. 이는 사람이 직접 라벨링(labeling, annotation) 작업을 하지 않고도 모델을 잘 학습할 수 있다는 장점이 있습니다. 이렇게 학습한 모델을 이용해서 fine-tunning하여 downstream task에 이용하면 효과적입니다. 최근 self-supervised learning 방법론들은 fine-tunning된 data augmentation 방법을 주로 사용하지만 이때 몇가지 문제점이 발생하며 문제점과 그에 대한 해결책을 소개해보겠습니다.
문제점 1
data augmentation 기법 조정을 위해서는 각 도메인 데이터의 사전 지식이 필요합니다. 이 말은 Domain A에서 ‘a’ data augmentation 방법이 효과적이라고 하면 ‘a’ 방법을 Domain B에 적용을 하게 될 경우 효과적이라고 보장을 할 수 없습니다. 오히려 augmentation 적용 안할때 보다 더 성능이 나빠질 수 있게됩니다.
좀 더 사실적인 예를 들어보면, Chest X-ray 영상 데이터를 이용해 이미지 분류 문제를 풀기 위해 인공지능 모델을 학습한다고 가정을 해보겠습니다. 영상의학과 의사들이 판독할 때 절때 Flip을 해서 판독하지 않습니다. 모델 학습과정에서 data augmentation 중 flip을 넣어서 학습을 해보면 성능이 오히려 덜 나올 가능성이 높습니다.
해결책 1
위 문제점의 해결책으로는 Mixup을 활용한 Contrastive Learning 방법이 있습니다. 이 방법의 특징은 도메인 특수성에 상관 없이 활용이 가능하며 다양한 도메인에서 도메인 관련 지식 없이도 높은 성능을 기록한것을 볼 수 있습니다.
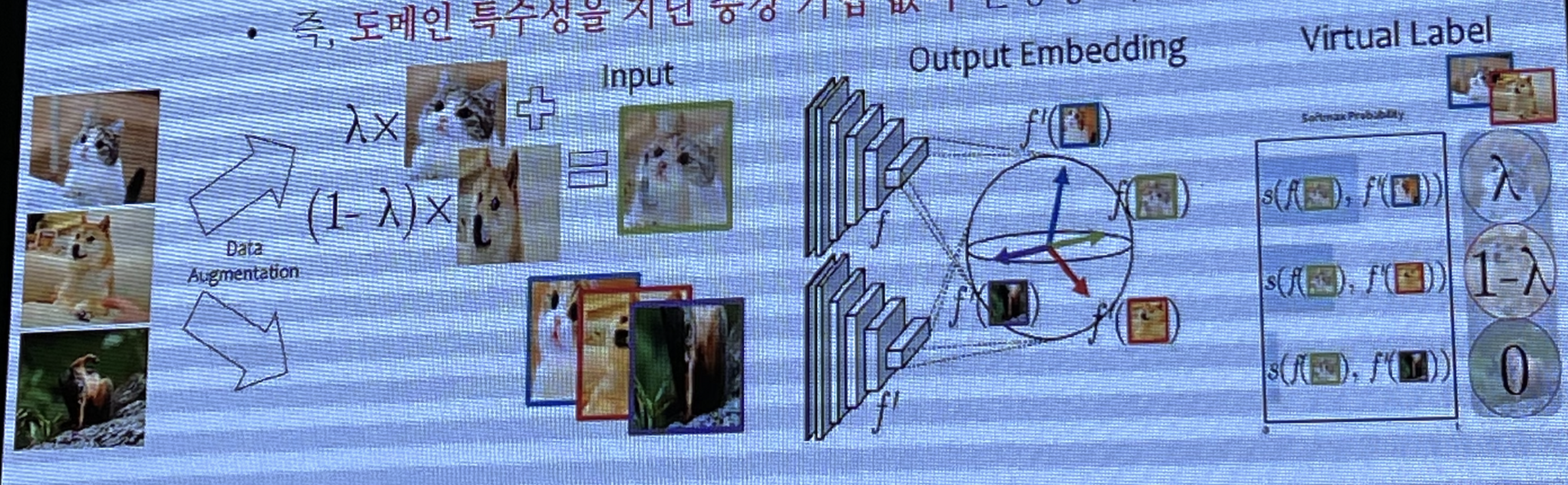
문제점 2
우리가 프레임워크를 이용해서 코드를 작성하고 모델을 학습할 때 여러 종류의 data augmentation을 사용해서 모델 학습을 진행합니다. 이때 어떤 data augmentation을 사용하느냐에 따라 downstream task의 성능에 영향을 미치게 됩니다.
해결책 2
Data Augmentation을 기반으로 한 self-supervised prediction을 통한 Transfer Learning을 개선하는 연구가 진행되었습니다. 이 연구는 NeurIPS 2021에서 소개된 Improving Transferability of Representations via Augmentation-Aware Self-Supervision 논문으로 정보 손실을 막기 위해 어떻게 데이터가 증강되었는지 예측하는 논문입니다.
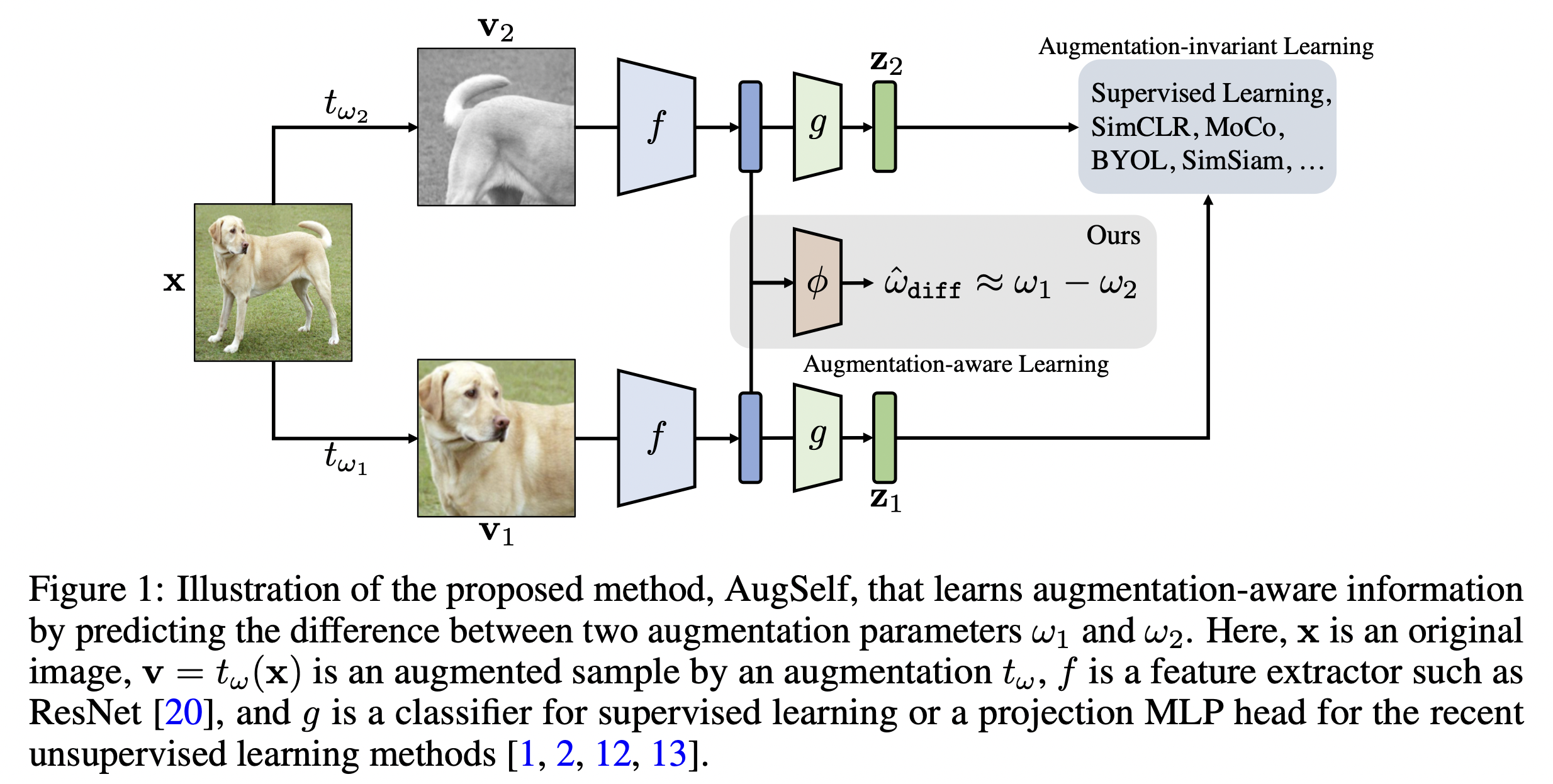
이 방법은 아래 표에서 보이는바와 같이 다양한 어플리케이션으로 전이 학습(Transfer Learning)에서 매우 효과적인것을 볼 수 있습니다.
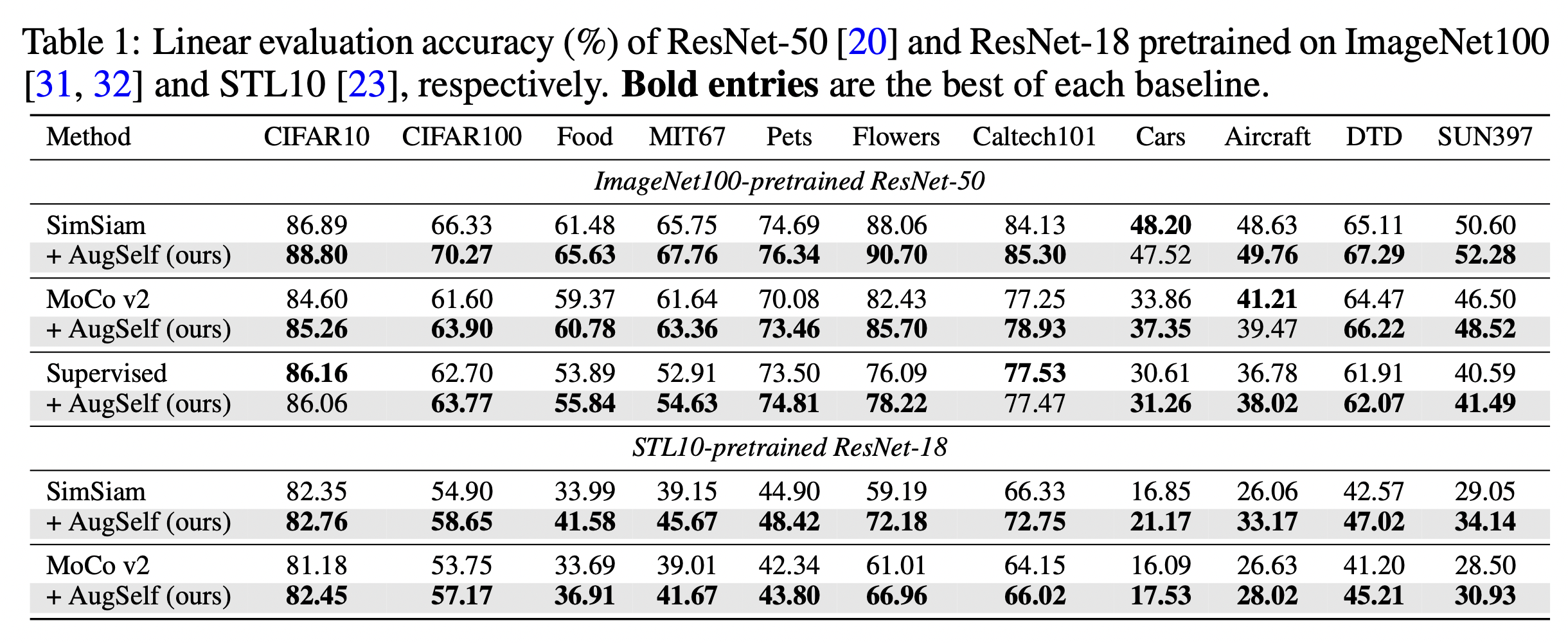
가상인간 기술
이번 세미나에서 가상인간 기술은 우리가 흔하게 알고 있는 source video에 target image를 입력하면 target image로 얼굴이 변경되는 Deep Fake 기술, 가상 영상에 가상 음성을 적용해서 AI 아나운서 같은 음성 합성 기술을 소개했습니다. 이번 발표는 다른 발표와는 다르게 프로젝트 결과물 위주로 소개해주셨습니다. 발표해주신 교수님께서 말씀해주신 것 중 기억에 남는 논문이 있는데. 그것은 StyleSpeech 논문으로 메타학습 기반 음성합성 기술로 ICML 2021에 억셉된 논문입니다.
기존 음성 합성 기술들은 GAN과 마찬가지로 많은 양의 데이터로 학습한 모델을 fine-tunning을 하는 경우가 많습니다. 하지만 StyleSpeech 논문은 StyleGAN의 AdaIN의 방법을 응용한 SALN(Style-Adaptive Layer Normalization)방법을 사용하여 새로운 사람의 목소리 스타일을 효율적으로 합성한 논문입니다.
또한 메타 러닝(meta-learning)을 접목시킨 Meta-StyleSpeech로 확정하여 아주 적은 양의 데이터로 새로운 사람의 목소리를 적용 가능하도록 하는 모델을 소개하고 있습니다.
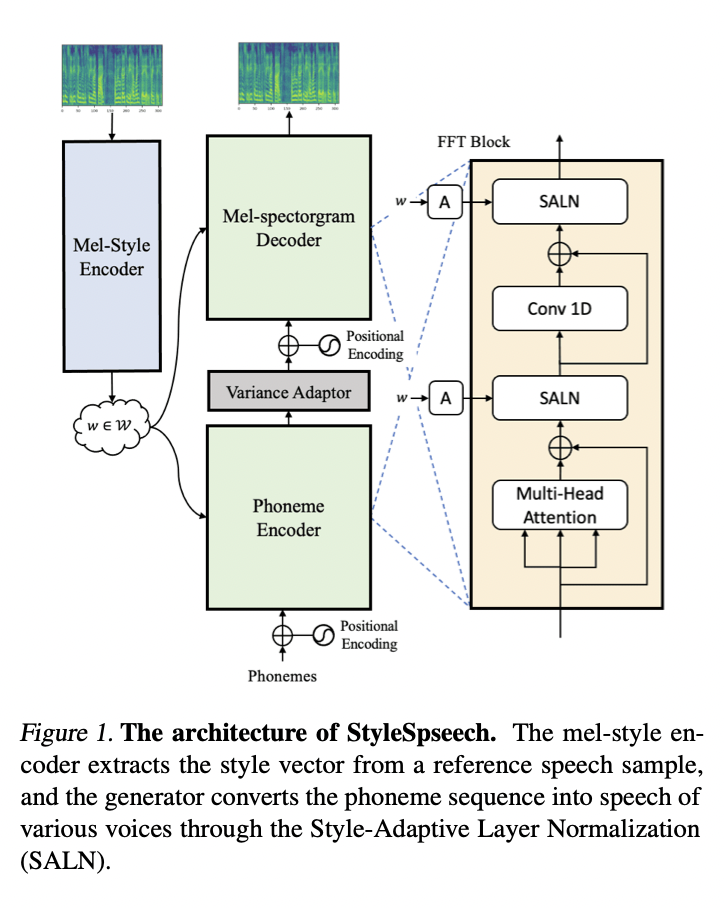
이 논문을 살표보니 개인적인 생각이지만 영상 합성 분야와 음성 합성 분야가 같은 방향성을 지니고 서로 좋은 특징들을 잘 응용하여 기술이 발전해나가는 것 같은 느낌을 받았습니다.