KAIST 김재철AI대학원 AI설명회 정리-2

이번 포스팅은 코엑스에서 개최된 2022 AI Expo에서 KAIST 김재철AI대학원 AI기술설명회 세미나 참석하고 간단하게 개인 의견을 포함하여 두서없이 정리한 내용입니다.
✔️ 설명 가능한 인공지능 동향 [Link]
✔️ 의료 인공지능의 동향 [Link]
✔️ 생성모델 기술 동향
☐ Federated learning [Link]
☐ 자기지도(self-supervised) 기반 비지도 학습 기술 [Link]
☐ 가상인간 기술 [Link]
정리한 내용이 많아 글은 총 3편으로 나누어서 작성하겠습니다.
생성모델 기술 동향
생성 모델은 두가지 테스크로 구분해볼 수 있다.
- 인식 테스크
- 생성 및 변환 테스크
- noise에서 어떤 이미지를 생성
- 서로 다른 스타일 별로 이미지를 변환
기술 동향
최근 생성모델을 이용한 기술은 이미지, 비디오와 더불어 텍스트 등의 2개 이상의 데이터를 함께 사용하는 Multimodal 모델을 대세(?)이다. 그 종류는 다음과 같다.
- 이미지 캡션 생성
- 텍스트 기반 이미지 합성 및 편집
- 음성 기반 얼굴 이미지 합성
- 벡터 표현형을 통한 이종 데이터의 통합 및 변환
ex) CLIP, DALL-E
Style Transfer

고해상도 영상 합성 기술 (StyleGAN2)
고해상도 이미지를 생성할 수 있는 PGGAN부터 StyleGAN, StyleGAN2, StyleGAN2-ada, StyleGAN3, StyleGAN-XL 등 여러 논문들이 나와있다.
아래는 제가 이전 회사에서 작성한 GAN 시리즈 중 일부인데 참고하면 좋을거 같습니다.
👀 StyleGAN 1편

CycleGAN

StarGAN
멀티 도메인 이미지 변환 기법이며 이미지 뿐만 아니라 비디오 상에서도 가능하다.
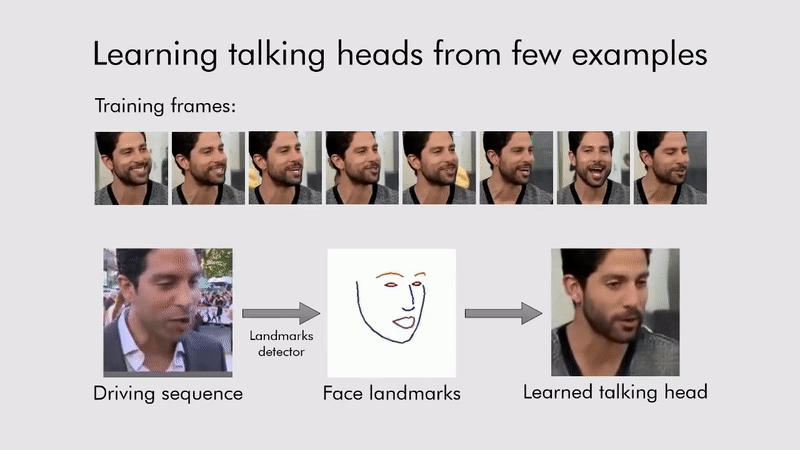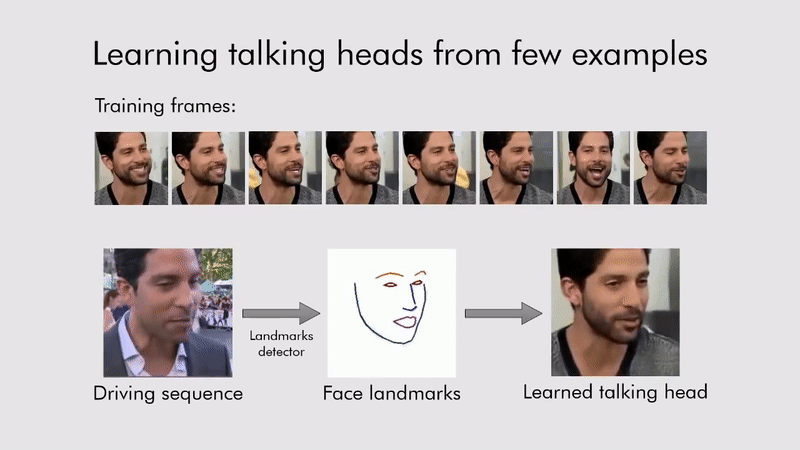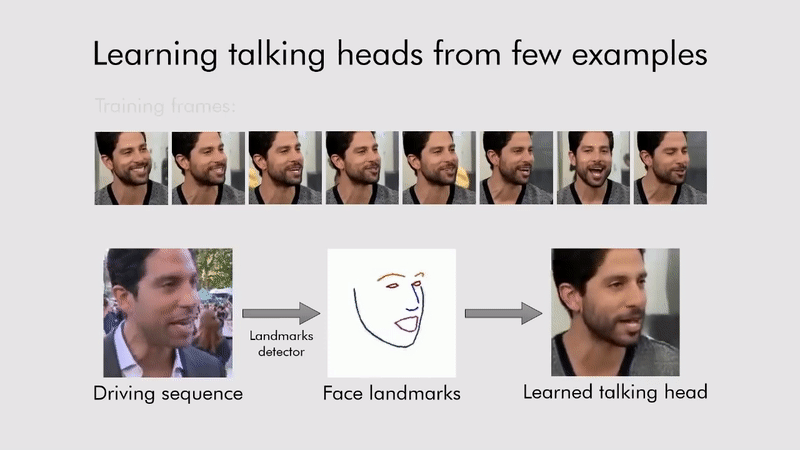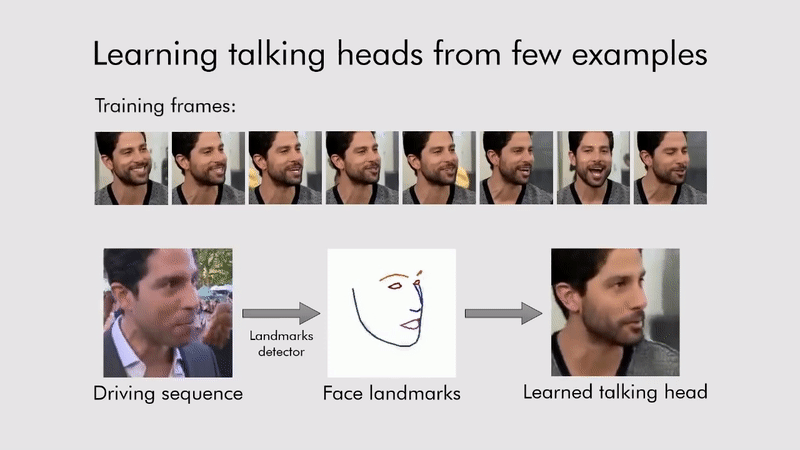
Deep fake
내가 변경 시키고 싶은 이미지 또는 영상에(target) 원하는 얼굴 이미지(source)를 입력으로 딥페이크 모델에 넣으면 원하는 얼굴이 합성된 상태로 결과가 나온다.
이 기술을 이용해서 Living portraits(움직이는 초상화)도 가능하다.
모션 주입 비디오 합성 (Everybody dance Now)
📄paper: Everybody Dance Now

인공지능 기반 자동 채색
자동 채색상의 엣지 블리딩 수정 기술
여러 컴퓨터 비전에서 자동 채색 기술에 관한 연구가 이루어 지고 있다. 스케치만 입력으로 주면 딥러닝이 자동 채색을 해줄때 특정 부분을 사용자가 수정하고 싶은 경우가 생길 수 있게 된다. 또한 딥러닝이 자동 채색을 해주면 경계가 모호한 부분에는 색이 번지는 현상이 일어나게 된다. 이런 현상을 컬러, 엣지 블리딩이라고 한다.
이런 경우 사람이 수정하고자 하는 영역에 경계선을 그리면 자동으로 수정이 가능하게 하는 방법이다.
Semantic 정보를 변경이 가능한 방법
다양한 Semantic information (무표정에서 웃는 표정, 남성에서 여성으로)를 변환하고 싶을 때 변경되는 영상 편집 방법이다.
📄paper: Closed-Form Factorization of Latent Semantics in GANs

실사 영상 편집
여름 이미지를 넣으면 겨울일때, 봄일때 다양한 계졀로 swapping 할 수 있는 기술
📄paper: Swapping Autoencoder for Deep Image Manipulation


가상으로 옷 갈아입기

📄paper: Swapping Autoencoder for Deep Image Manipulation
📄paper: VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization
2차원 영상에서 3차원 영상으로 복원
Attention 기반 이미지 캡션 생성
- 주어진 이미지가 있을 때 텍스트 이미지를 설명하는 문장을 생성하는 분야.
📄paper: Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
📄paper: Show and Tell: A Neural Image Caption Generator

이 이외에도 문장 입력을 통한 자동 채색, Text-to-Image Generation(DALL-E, DALLE-2), 텍스트 기반 이미지 편집(Style CLIP) 등의 연구들이 존재한다.
향후 연구 방향
- Support for real-time, multiple interactive interactions
- Reflecting higher-order user intent in multiple sequential interactions
- Revealing inner-workings and interaction handle
- E.G., explicitly using (interpretation-friendly) attention module
- Better simulating user inputs in the training stage
- Incorporating data visualization and advanced user interfaces
- Leveraging hard rule-based approaches
- Incorporating users’ implicit feedback and online learning
기타 인공지능 분야의 최신 동향
- 초거대 AI 모델
더 많은 데이터 + 더 큰 딥러닝 모델 + 더 많은 GPU 리소스 - 실제 활용될 때의 이슈 대두 및 보완책
- 인간과 인공지ㄴㅇ 간의 소통 (인공지능 판단의 근거 제시, 사용자 피드백 수용)
- 인공지능 모델의 취약점 및 보안 관련 문제
- MLOps
- 머신러닝 모델을 서비스에 적용하는 전체 파이프라인을 다룸
- 실제로 딥러닝 모델을 프로그램으로 짜고, 그 모델을 학습해서 성능을 높이는 과정은 전체 과정 중 작은 일부만을 차지함.
- 그 보다는 학습 데이터의 확보 및 정제, 라벨링, hyperparameter tunning, 딥러닝 하드웨어 구성, 모델 개인화 및 경량화, 새로운 데이터에 대한 active learning 기반의 추가 학습 등의 다양한 다른 과정이 훨씬 더 중요해짐.