KAIST 김재철AI대학원 AI설명회 정리-1

이번 포스팅은 코엑스에서 개최된 2022 AI Expo에서 KAIST 김재철AI대학원 AI기술설명회 세미나 참석하고 간단하게 개인 의견을 포함하여 두서없이 정리한 내용입니다.
✔️ 설명 가능한 인공지능 동향
✔️ 의료 인공지능의 동향
☐ 생성모델 기술 동향 [Link]
☐ Federated learning [Link]
☐ 자기지도(self-supervised) 기반 비지도 학습 기술 [Link]
☐ 가상인간 기술 [Link]
정리한 내용이 많아 글은 총 3편으로 나누어서 작성하겠습니다.
설명 가능한 인공지능 동향 (Explainable AI 이하 XAI)
XAI가 필요한 이유
일반적으로 인공지능 모델에 던질 수 있는 질문을 다음과 같이 정리할 수 있습니다.
- 많은 weights를 이용해서 딥러닝 설명하는 것이 가능한가?
- 딥러닝이 아닌 다른 기계학습 모델도 설명하는 것이 가능한가?
- XAI을 이용하면 기존 AI 모델 성능을 올릴 수 있는가?
- 어느 분야에 XAI를 적용할 수 있는가?
필요 분야
필요 분야는 크게 아래와 같이 정리해볼 수 있다.
- 제조 - 제조 공정의 상태를 설명
- 의료 - 중환자의 상태를 설명
- IT - 생성 모델의 원리 설명
- 금융 - 고객 신용평가 모델의 이유를 설명
부족한 데이터로 인공지능 모델을 학습하거나 잘못된 방향으로 모델을 학습하는 경우 성능이 잘 나올 수도 있겠지만 신뢰할 수 없는 모델일 수 밖에 없으며 대부분 학습이 제대로 안될것이다.
이런 경우 우리는 why?? 라는 질문을 내던져볼 수 있다.
왜 학습이 잘못 되었는지 설명이 가능하나?어떤 이유로 인해 학습이 잘 되었으며 왜 결과가 잘 나오는지 설명이 가능하나?
이러한 이유로 인해 Explainable AI 즉, 설명 가능한 인공지능이 필요하다.

고위험 분야에 XAI 관련 법안 발의
최근 고위험 분야에서 XAI 법안 발의가 되었다고 한다. 따라서 앞으로는 인공지능 모델을 이용하여 사업화를 진행한다면 결과가 더 투명해야 하고 이런 법안들을 잘 통과 시켜야 한다고 언급을 해주셨다.
해결 방안
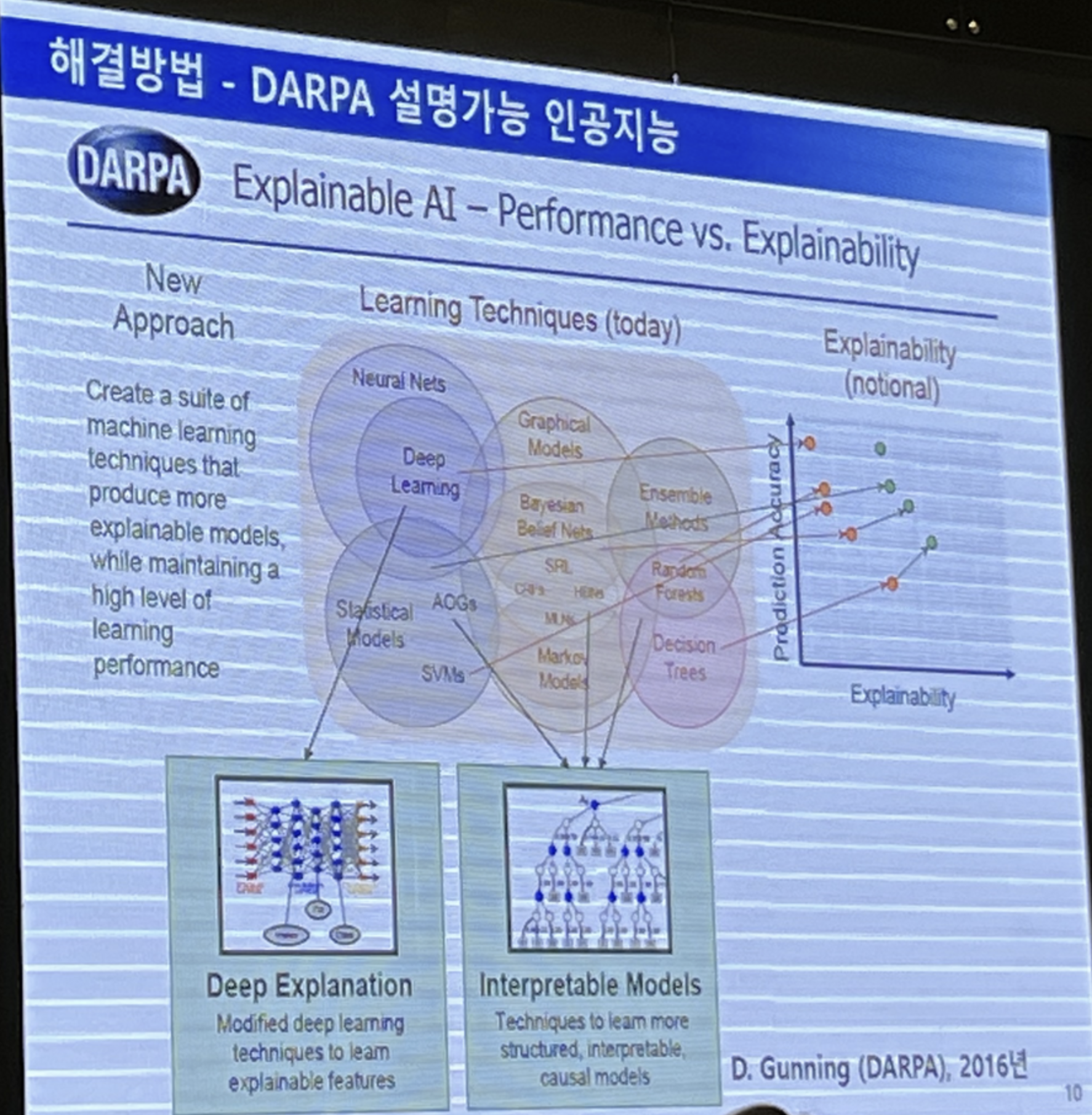
딥러닝 분야
딥러닝 분야에서 XAI를 이용한 해결 방법으론 다음과 같다.
- 입력에 대한 설명
- 출력에 대한 설명
- 내부에 대한 설명
기계학습 분야
입력을 변경할 때 출력이 어떻게 변경 되는가에 대한 설명이 필요하다.
ex) 판다에 노이즈를 넣은 결과 다른 결과로 인식하는 경우
방법
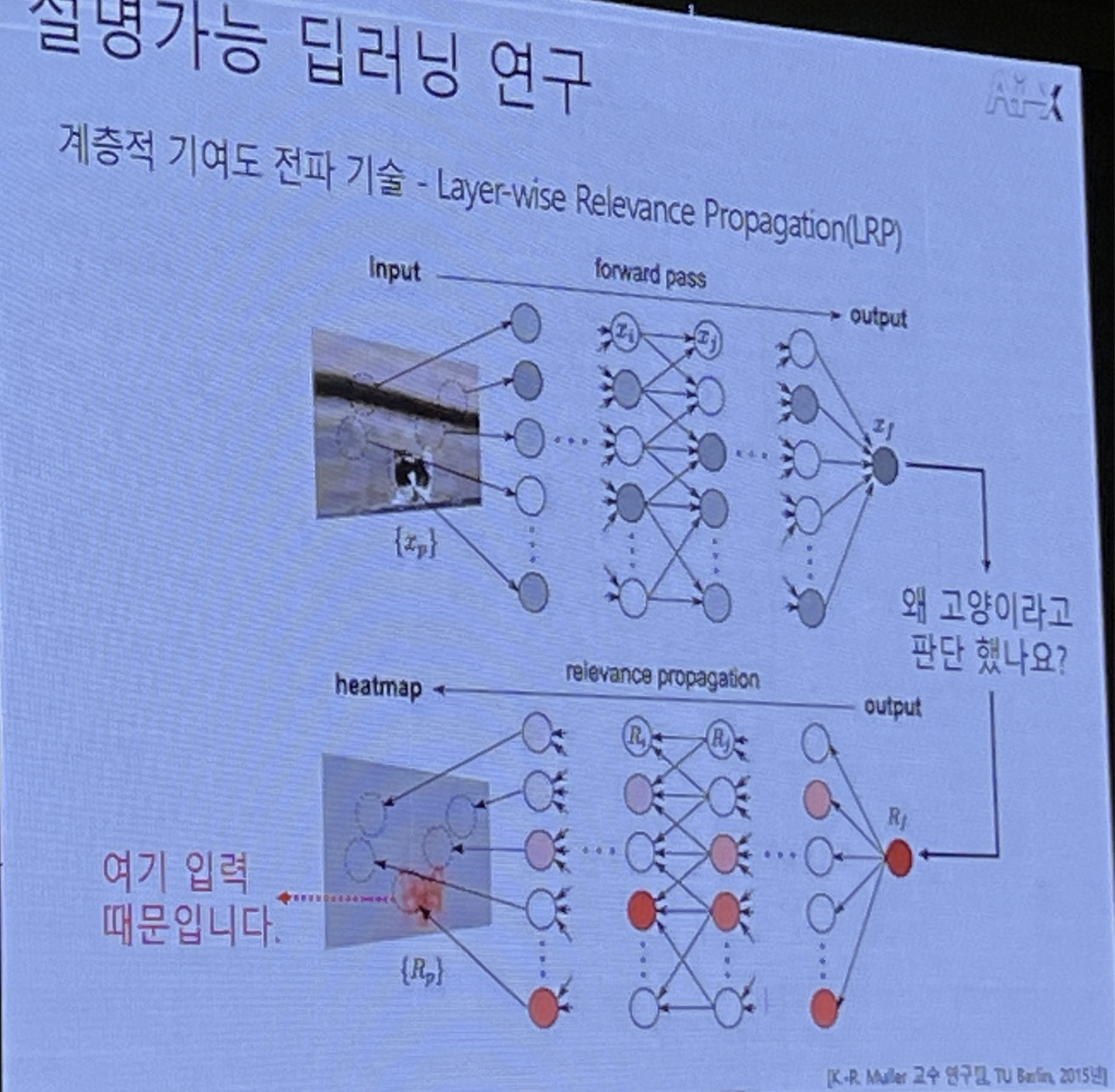
Layer-wise Relevance Propagation(LRP)
LRP는 입력 데이터가 인공지능 모델의 특정 물체를 잘 인지했는지 기여하는 입력 기여도 평가법이다. 인공지능 모델에서 각 layer들은 선형 모델(linear model)로 이루어져 있다. 그래서 layer마다 얼마나 결과에 기여했는지 계산하는 방법이다.
이 내용에 대해 잘 정리가 된 블로그의 문구를 이용하면 다음과 같다.
LRP는 타당성 전파와 분해 방법을 사용해 모델을 해부하며, 출력값에서 부터 시작해 타당성 점수 또는 기여도라 불리는 relevance score를 입력단 방향으로 계산해 나가며 그 비중을 분해하는 방법이라고 한다.
(출처: https://velog.io/@tobigs_xai/3주차LRPLayer-wise-Relevance-Propagation)
의사결정 설명이 보존되는 네트워크 압축 알고리즘
📄paper: Attribution preservation in network compression for relible network interpretation
네트워크가 잘 압축 되면서도 설명성을 유지할 수 있는 기술인 논문이다. 이 논문에서는 압축 할때도 설명성이 필요하다 라고 언급을 하고있다.
반사실적 추론 모델을 이용한 지도학습 자료 보강 (서울대)
Attention model로 사람이 마스킹 해주는 것 대신 자동으로 어떤 텍스트를 보고 잘 되는것인지 설명하는 모델 방법이다.
포스코 고로 상태를 예측하고 설명하는 인공지능 기술
뉴스 기사 참고 → Link
세미나에서 세계 초초로 설명 가능한 인공지능 표준을 카이스트에서 제안했고 최근에 그 제안이 받아드려 지고 있다고 했다.
여기까지 설명 가능한 인공지능(XAI)을 이용하면 다음과 같은 질문을 해볼 수 있다.
Q. 설명 가능한 인공지능을 하면 성능이 좋아지나?
A. 인공지능 모델이 배를 보고 배라고 정답을 내야하는데 배는 안보고 주변 환경인 바다를 보면서 배라고 답을 내놓는 경향이 있다. 이는 데이터가 얼마나 bias 되어있는지를 말할 수 있고 데이터가 얼마나 중요한 부분을 보고 물체를 결정했는 건가 라는 것을 말할 수 있다. 이는 인공지능 모델에 대한 검증이 가능하다 라고 말을 할 수 있다.
GAN Dissection

생성 모델에서도 설명 가능한 인공지능이 필요하다고 했다. 그에 대한 논문은 다음과 같다.
📄paper: GAN DISSECTION: VISUALIZING AND UNDERSTANDING GENERATIVE ADVERSARIAL NETWORKS
이 세미나에서 생성 결과에 오류가 있는 경우. 그에 대한 원인과 해결책을 설명해 주셧는데 정리를 해보면 다음과 같다.
원인
생성 모델은 Discriminator(D)와 Generator(G)로 구성되어 있다. D는 real인지 fake인지 구분하는 것이 목표며 G는 D를 속이는 방향으로 학습하여 이미지를 생성하는게 목표이다. 생성된 이미지와 실제 학습 이미지를 D가 구분이 어려워 지는 경우가 발생할 수 있으며 이는 생성에 문제가 있는 이미지와 문제가 없는 이미지를 D가 구분하기 어려워 하여 생성 결과에 오류가 생기게 된다고 한다.
해결책
D가 생성된 이미지와 학습 데이터와 구분이 어려워져 생성 결과에 오류가 생기는 경우 ‘논문’에서는 Discriminator에 Grad-CAM 적용하여 해결 했다고 한다. 이 내용에 대한 자세한 설명은 다음과 같다.
우선 feature map을 upsampling한다. 이후 grad-cam이 찍힌 mask 영역과 IoU(Intersection ovet Union)을 계산하여 구분이 어려워 지는 부분, 즉 결함과의 관계를 score화 한다. 이런 방법으로 접근하면 Discrimintor의 어느 layer때문에 구분을 잘 못하며 그로 인해 이상한 이미지를 생성하는지에 대한 activation rate를 찾을 수 있고 이 값을 이용해서 문제가 발생한 layer의 activation value를 off 시켜주면 정상적으로 이미지가 잘 생성 된다고 한다.

의료 인공지능 동향 (AI for Healthcare)
목표
Use AI to improve healthcare for all 즉, 인공지능을 환자, 의사에게 도움이되는 의료 인공지능을 개발하는게 목표라고 한다.
의료 데이터는 크게 두가지로 나뉠 수 있다.
- table data
- image data
table data는 환자 의료기록 정보, 판독 음성, 판독문, 생체 신호 등을 볼 수 가 있고. image data는 말 그대로 MRI, X-ray, CT 같은 의료 영상 데이터다.
이번 세미나에서는 EHR데이터로 할 수 있는 것에 중점을 두고 발표를 하신거 같은 느낌이 들었다.
EHR(electronic health records)
EHR 데이터는 오랫동안 쌓아온 데이터들이 많은 것이다. 뿐만 아니라 최근들어서는 HW 성능 향상으로 인해 더 정밀한 값을 얻어 질 좋은 데이터를 확보하게 될 것이다. 이런 데이터들을 이용하면 좋은 결과를 얻을 수 있을 것 이라고 기대를 한다고 한다.
EHR 데이터로 할 수 있는 연구 중 대표적으로는 예측 문제를 뽑을 수 있다. 예를 들어보면 내원한 환자가 미래에는 어떤 이유로 아플 예정인지, 언제 내원하면 좋을지, 어떤 약을 처방하면 좋을지 등에 대한 예측을 하는 것이다.
하지만 문제점이 있다. 아무리 데이터가 많아도 각 병원마다 사용 포멧이 다르고 질병 코드명도 다르다. 이런 문제점을 극복하고자 최근에는 어짜피 감기로 내원했는지, 어디가 아픈지 등 모든 정보들은 그 질병 정보에 대한 키워드가 있을 것이다. 따라서 모든 질병 코드명들을 표준화된 vector로 벡터화(vector representation of codes) 하여 연구를 진행하고 있다. 이로써 어떤 질병은 어떤 질병과 연관 되어 있는지 학습을 통해 확인할 수 있으며 EHR 데이터로 효과적인 예측 문제 연구를 수행할 수 있게 되었다.
Limitation RNN
모든 정보를 벡터화 한 데이터를 이용하여 초기에는 RNN기반으로 연구가 진행되었다. 어느정도 성능은 잘 나오지만 한계점이 존재하는데 그 한계즘은 다음과 같다.
90% 이상으로 수술이 필요하다고 했는데 왜 그런지 설명이 가능해야 한다. 하지만 RNN은 그 설명이 힘들다는 한계점이 존재한다. 모든 분야가 마찬가지겠지만 특히 의료 분야는 왜 이런 결과를 도출했는지 설명이 가능해야 신뢰를 할 수 있다. 이런 부분은 앞으로 해결해야할 연구 방향이라고 언급을 해주셨다.
EHR + Medical Image
의료 데이터가 있으면 그 데이터를 판독한 판독문도 존재한다. EHR 데이터를 이용해서 또는 의료 영상 데이터만을 이용해서 인공지능 모델을 학습하기 보단 두개의 데이터를 같이 학습한 연구를 진행해본 예시이다. 이와 같이 학습하면 인공지능 모델이 직접 의료영상 데이터만을 보고 소견서를 자동으로 작성하는 것이 가능해진다.
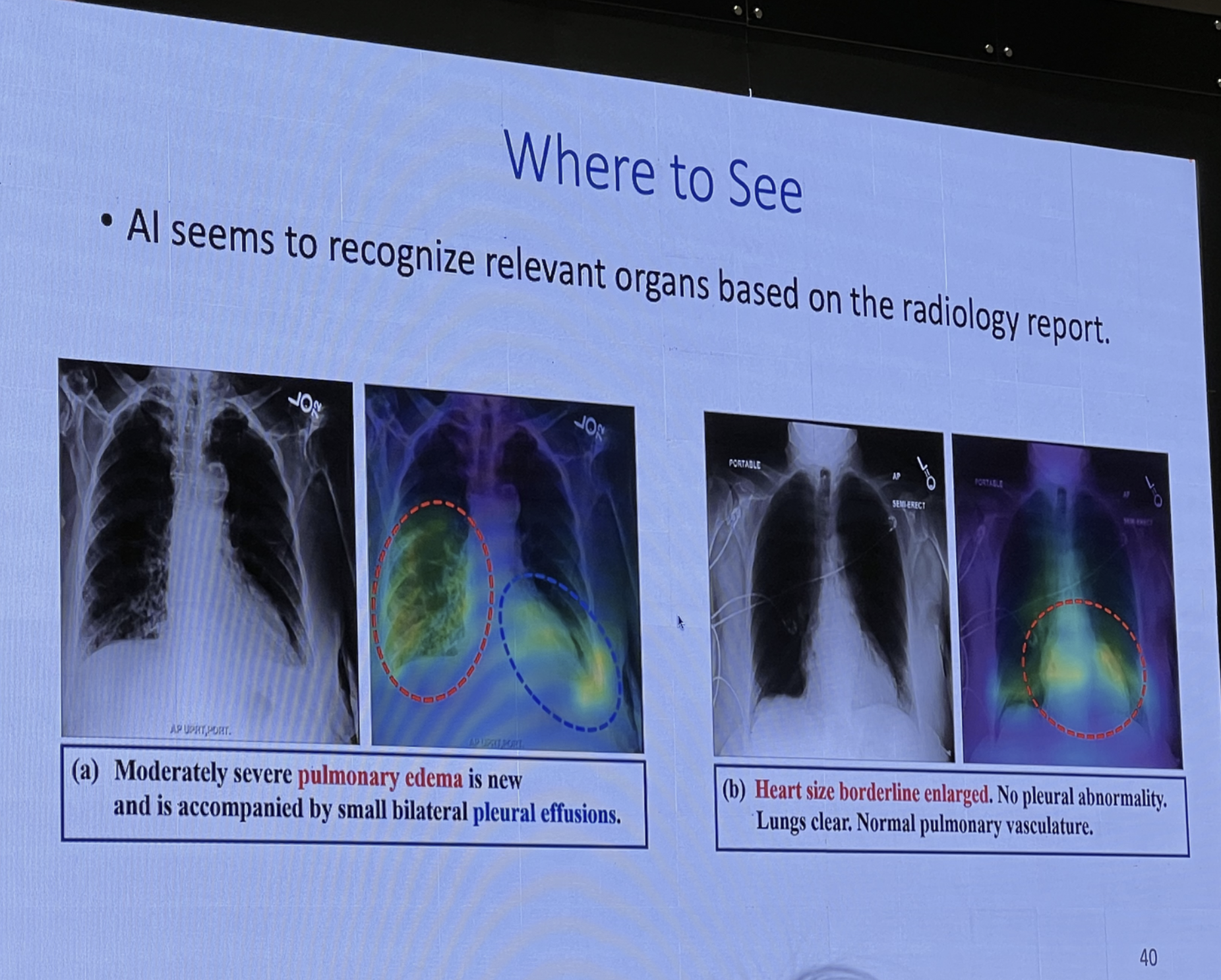
위 데이터는 의료 영상 데이터와 판독 내용 함께 입력으로 넣어주었더니 인공지능 모델이 특정 키워드만 보고 자동으로 어떤 부분을 보고 질병이라고 말을 해주고 있는 것인지 학습하는 예시이다.
의료 데이터는 각 의료 장비, 병원마다 데이터들이 다 달라서 데이터 호환성이 매우 안좋다. 그래서 여러 병원 데이터를 이용해서 큰 모델을 학습하고 싶어도 힘든게 현실이다. 하지만 생각을 해보면 병원의 질병 code는 달라도 ‘고혈압’과 같은 질병 자체의 내용은 같을 것이다. 그래서 ‘고혈압’ 단어 자체를 인식하여 연구를 진행하면 병원간의 포멧이 달라도 데이터 호환성 문제 해결이 가능하다.
Zero-shot & Few-shot Transfer
A 병원에서 학습한 모델을 B 병원에다가 낸다. 이때 재학습 하는게 아니라 테스트셋을 바로 돌려보면 성능이 잘 나오는 경우가 많다. 즉 호환성이 올라가는 결과를 볼 수 있다.
Structured EHR
환자 테이블, 약품 테이블 등 테이블 데이터에 대한 정보를 다 엮어서 무언가를 파악하기는 현실적으로 어렵다. 그래서 EHR-AQ(AI 스피커 , 챗본 같은 것을 활용)을 이용하면 파악하기 좋을거 같다 라고 말을 하고 있다. 이를 활용해서 환자 입장에서 볼 때 환자가 여러가지를 물어볼 수 있을 것으로 기대함.
테이블 형태를 그래프 형태로 변경하면 지식 그래프로 변환되고 이런 그래프를 탐색해가며 찾는다. 그러면 사람의 언어를 기계어로 번역하는 연구 사례처럼 잘 이루어 질 것으로 보인다. (need to go beyond text to sql)
Industry Application
딥마인드(2019년 연구 결과) - AI assisted clinical care pathway
구글헬스(Based on longitudinal EHR data from two hospitals)
- Inpatient mortality prediction
- 30-day readmission prediction
- length-of-stay prediction
- discharge diagnoses prediction ⇒ 진짜 목적은 서로 다른 두 병원의 포멧이 다른 경우 어떻게 극복을 할것인가에 초점을 두고 연구 진행
- 서로 스키마가 다르니까 중립적인 스키마를 사용 (Common Data Model ex, OMOP $ FHIR)
- 일일이 수작업을 진행해서 결국 두 병원의 데이터를 같은 포멧으로 변환 함.
- 결국, 병원마다 모델을 만들 필요가 없어졌으며 성능이 괜찮게 나옴.
Apple healths (Arrhythmia Detection)
심전도 예측
Amazon comprehed medical (amazon care)
B2B 서비스 (이런게 훨씬 더 리스크가 덜하고 바로 사업하기 좋은 아이템 이라고 하셨다)
- NLP로 aws에다가 api를 제공해서 내 의료 문서를 업로드 하면 그것을 태깅(객체인식)을 해주고 서비스 공개.
- 병원, 제약사, 보험사 같은 경우 medical text를 대형으로 분석하는 경우가 많은데 그럴대 api를 이용하면 저비용으로 충분이 가능하다. 라는 서비스를 제공.
Deepmind AlphaFold
- 단백질의 구조를 자동으로 예측하는 시스템 개발함.
- 문서만 보여줘도 단백질 구조를 예측함 → 약을 만듬 → 3D를 이용해서 어는 부분이 취약한지도 알 수 있음.
MELLODDY (제약)
EU-lead massive drug discovery project