[AnoGAN]Unsupervised Anomaly Detection with GAN
- 이번 포스팅은 티스토리에서 깃블로그로 이사 후 티스토리에 정리했던 내용에서 내용을 추가해서 작성한 글 입니다. 이전 글은 AnoGAN 정리글_Tistory에서 보실 수 있습니다.
- 기존 Anomaly Detection은 Supervised Learning으로 접근했지만 AnoGAN은 GAN을 이용한 Unsupervised Learning 방법으로 접근하여 Anomaly Detection하는 논문입니다.
- Paper 원문: Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
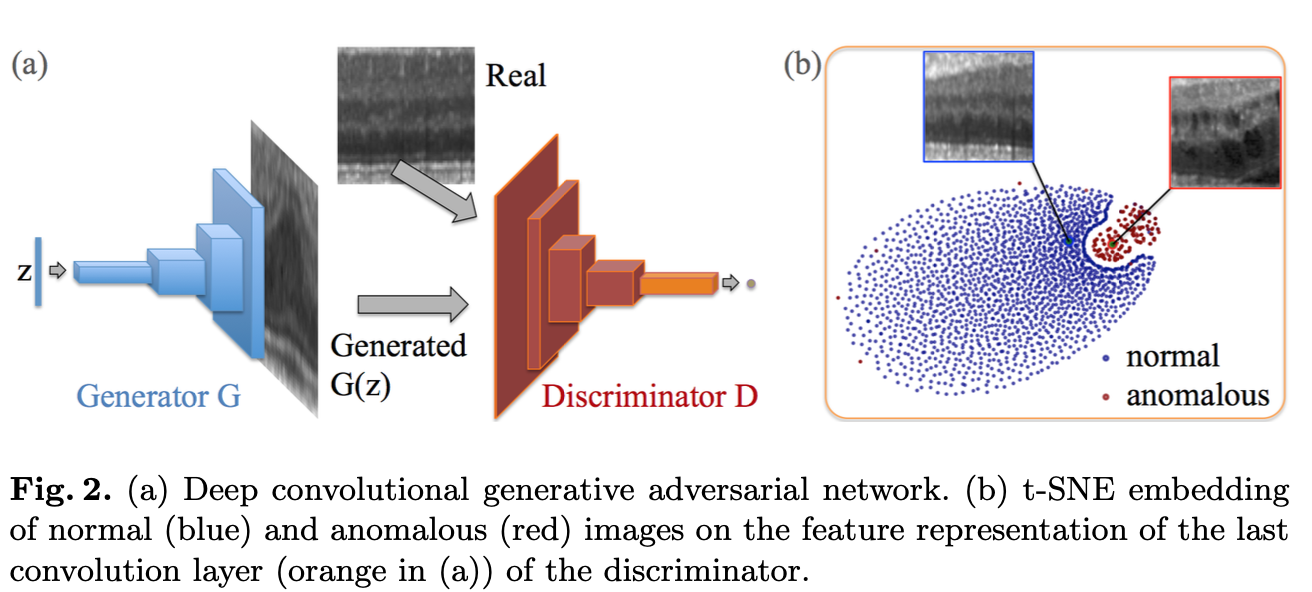 # Introduction
# Introduction
GAN이란?
GAN 학습 과정은 Discriminator가 Real/Fake를 잘 맞추도록 학습한 후 Generator가 생성한 Fake image가 Discriminator를 속여 Real이라고 말하게끔 하도록 하는 학습 과정입니다.
DCGAN
⎮ CNN vs MLP
MLP(Multi-Layer Perceptron)
- 특징: 3차원 데이터를 1개의 Vector로 풀어서 인식합니다.
- 단점: 이미지 위치 정보를 무시하게 됩니다. (Feature loss 발생)
CNN(Convolutional Nerual Network)
- 특징: 3차원 데이터 입력을 그대로 사용해 위치 정보가 반영됩니다.
⎮ Discriminator
Convolution 연산을 통해 데이터의 차원을 줄이는 과정입니다. 어떻게 보면 Encoder의 모델 구조와 비슷하다고 볼 수 있습니다.
⎮ Generator
Generator는 Latent Space를 입력으로 넣어주면 차원을 확장 시키는 방법으로 모델 구조를 구성합니다. 이때 사용하는 함수는 Pytorch 기준 nn.ConvTranspose2d를 사용합니다. 즉, Deconvolution 방식으로 모델이 구성됩니다.
⎮ DCGAN 특징
Generator는 이미지를 외워서 보여주는 것이 아니다. (Memorization이 안일어난다.)
Paper를 읽어보면 “walking in the latent space”라는 문구가 나옵니다. 만약 G가 Memorization이 발생된다면 latent vector를 조금씩 바꿀 때 이미지가 변형되 못할 것 입니다.Memorization이 일어난 경우는 어떤 경우인가?
Generator가 유의미한 특징들을 학습하지 않고 overfitting이 발생되 데이터와 1:1 mapping이 발생하는 Identity Mapping 학습이 이루어지게 됩니다.walking in the latent space
latept space 내부에서 vector값을 조금씩 변경하면 부드럽게 이미지들이 변화되는것을 확인할 수 있는 그림 입니다.

AnoGAN
Abstract
의료데이터에서 disease progression과 treatment monitoring에 이미지를 검출하는 model을 구하는 것은 어려운 일이다. 기존 모델은 automating detection을 위해 annotation이 이루어진 많은 양의 데이터를 기반으로 Supervised Learning 방식으로 진행했다. Supervised Learning은 annotation과 이미 알려진 것들에 대해서만 detection이 이루어 지는 단점이 존재하다. 그래서 이 논문은 Unsupervised Learning 방식으로 학습을 진행한 후 Anomaly Detection 과정이 이루어진다. 이 논문에서 제안한 AnoGAN은 다양한 Normal Data로 학습한 DCGAN과 Image space 안에서 latent space의 mapping을 기반으로 Anomaly score를 계산한다. 새로운 데이터가 들어오게 되면 model은 anomaly한 부분에 labeling하게 되고 Normal image로 학습된 distribution에 적합한지 image patches에 anomaly score를 나타낸다. 이 방식은 망막의 광학 단층 촬영 영상에 적용한 결과 망막 유체 또는 반사성 초점을 포함하는 이미지와 같은 Abnormal image을 정확하게 식별함을 확인했다.
AnoGAN이 등장한 계기
이 논문에서 사용된 데이터는 의료 데이터 입니다. 의료현장, 산업현장 모두 공통적으로 Normal 데이터는 많지만 Abnormal 데이터는 부족한 경우가 많습니다. 지금까지 Anomaly Detection을 하기 위해 Supervised Learning 방법으로 진행했지만 이는 Anotation된 데이터가 많이 필요하다는 단점이 발생되게 됩니다. 그래서 Unsupervised Learning 방법 중 GAN을 이용한 Anomaly Detection을 진행하게 되었습니다.
좀 더 쉽게 정리를 해보면…
Discriminator는 입력 이미지가 True/False의 확률을 구하는 classifier라고 생각하시면 됩니다. 여기서 Unsupervised Learning으로 접근하는건 굳이 Annotation 과정을 할 필요 없이 모델 알아서 처리를 하는 과정으로 접근한다는 것 입니다. Discriminator을 학습할 때 그 discribution 안에 속하지 않은 데이터들은 다 Fake라고 하지 안을까? 라는 아이디어에서 Normal Discribution의 outlier detection을 할 수 있는 AnoGAN이 탄생하게 된 것 입니다.
Unsupervised Learning으로 접근한 이유
⎮ Data Imbalance Problem
위에서도 잠깐 언급을 하긴 했지만 의료데이터, 산업현장 데이터는 Normal 데이터는 많지만 Abnormal 데이터는 부족한 점이 특징입니다. 그래서 Supervised Learning으로 문제를 해결하려면 우선적으로 Data Imbalance 문제를 해결해야합니다. 이런 수고스러움을 덜고자 Unsupervised Learning 방법으로 접근하게 되었습니다.
⎮ Annotation 작업의 엄청난 비용
아무래도 의료데이터는 비전문가들이 annotation을 할 수 없다는 제한점이 있다보니 전문가들이 직접 annotation을 해야합니다. 해보신 분들은 하시겠지만 엄청난 시간과 비용을 투자해야한다는 단점이 발생합니다. 또한 균일하게 완벽하게 100%로 annotation을 한다는 보장이 없다보니 데이터 마다 성능차이가 많이 발생할 수 있다는 문제가 존재합니다. 그래서 이런 과정을 하지 않고 Normal 데이터로만 학습 한 후 Normal Discribution에서 벗어나는 데이터가 들어올때 어느 부분이 outlier인지 detection 해주는 방법으로 진행했습니다.
AnoGAN의 동작 원리
⎮ 정상 데이터로 GAN 학습
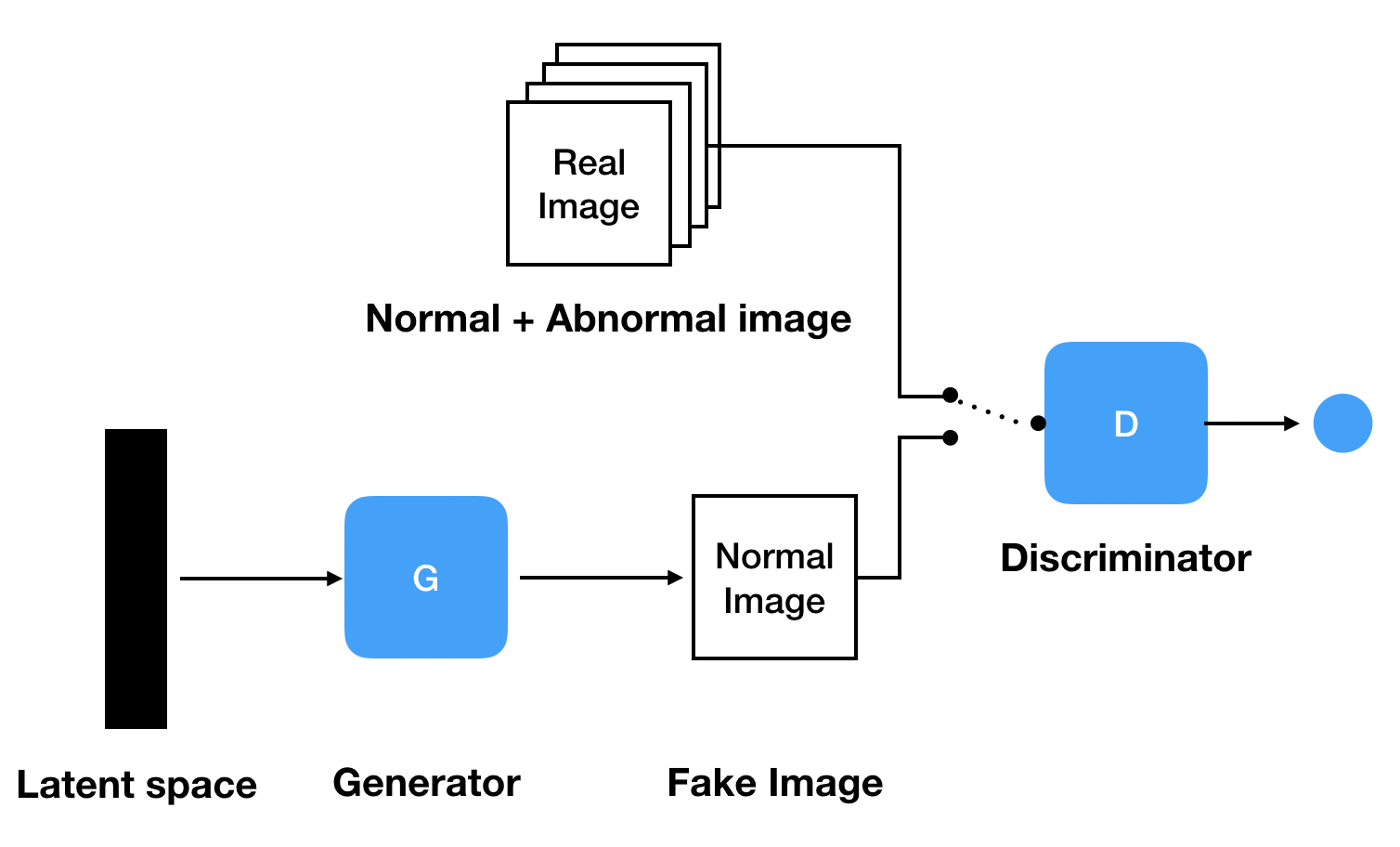 Generator Model이 어떤 latent space가 들어와도 Normal 이미지를 잘 생성할 수 있도록 GAN을 Normal 데이터로만 학습시켜야 합니다. 그러면 Generator Model은 Normal Manifold를 학습하게 되어서 Normal 데이터만 생성하게 됩니다.
Generator Model이 어떤 latent space가 들어와도 Normal 이미지를 잘 생성할 수 있도록 GAN을 Normal 데이터로만 학습시켜야 합니다. 그러면 Generator Model은 Normal Manifold를 학습하게 되어서 Normal 데이터만 생성하게 됩니다.
⎮ 최적의 Z값 찾기
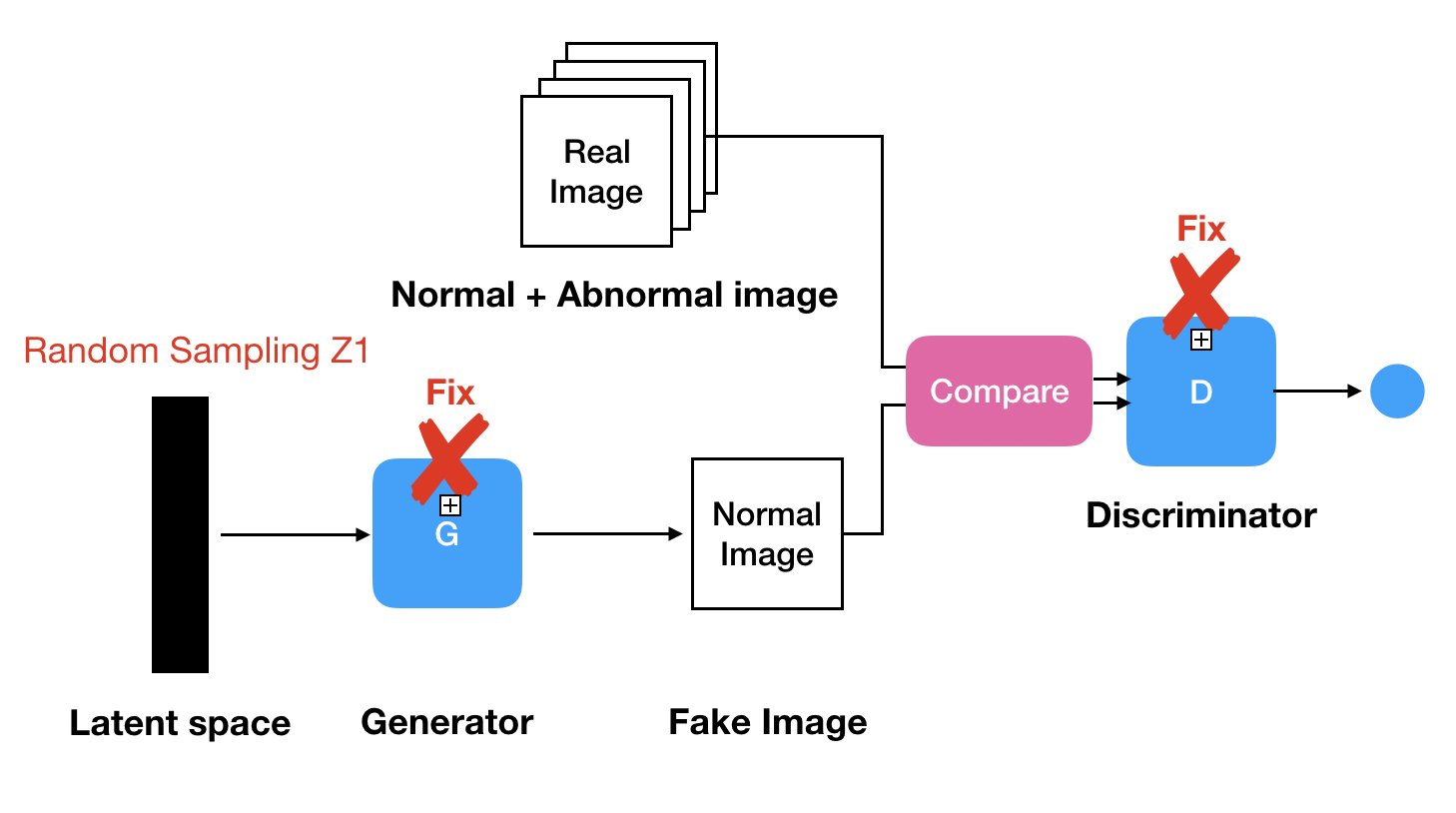 Generator와 Discriminator의 Parameter를 Fix시켜 더이상 Update 해주지 않는 상태로 latent vector $z_1$을 random sampling 시킨 후 Generator에 입력 데이터로 넣어준다 $G(z_1)$. Generator는 Normal 데이터의 Manifold를 학습한 상태여서 Normal image를 생성하게 된다.
Generator와 Discriminator의 Parameter를 Fix시켜 더이상 Update 해주지 않는 상태로 latent vector $z_1$을 random sampling 시킨 후 Generator에 입력 데이터로 넣어준다 $G(z_1)$. Generator는 Normal 데이터의 Manifold를 학습한 상태여서 Normal image를 생성하게 된다.
⎮ Residual Loss
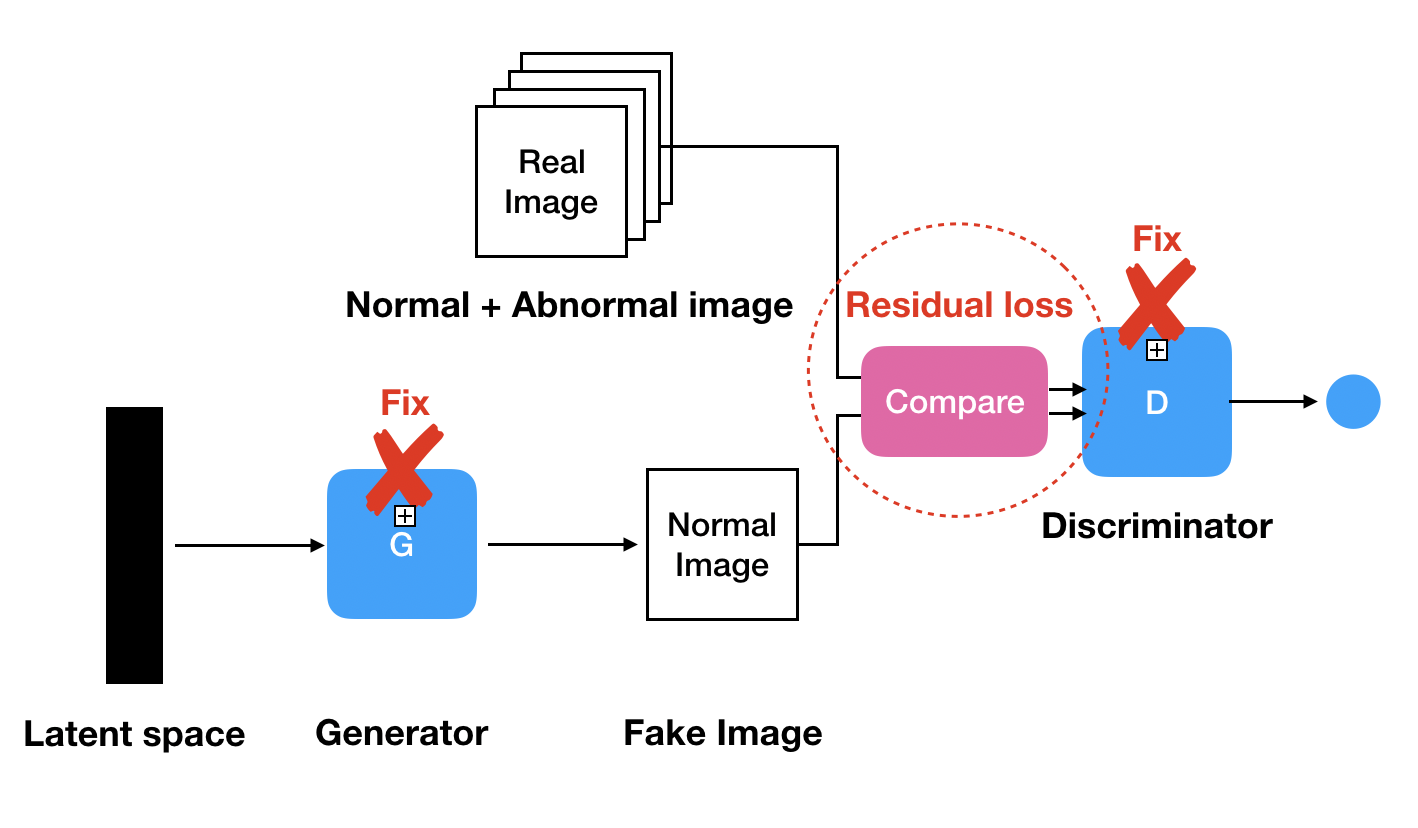 query image와 $G(z_1)$ 사이에서 다른 부분이 있는지 그 차이를 비교하는 과정입니다.
query image와 $G(z_1)$ 사이에서 다른 부분이 있는지 그 차이를 비교하는 과정입니다.
⎮ Discrimination Loss
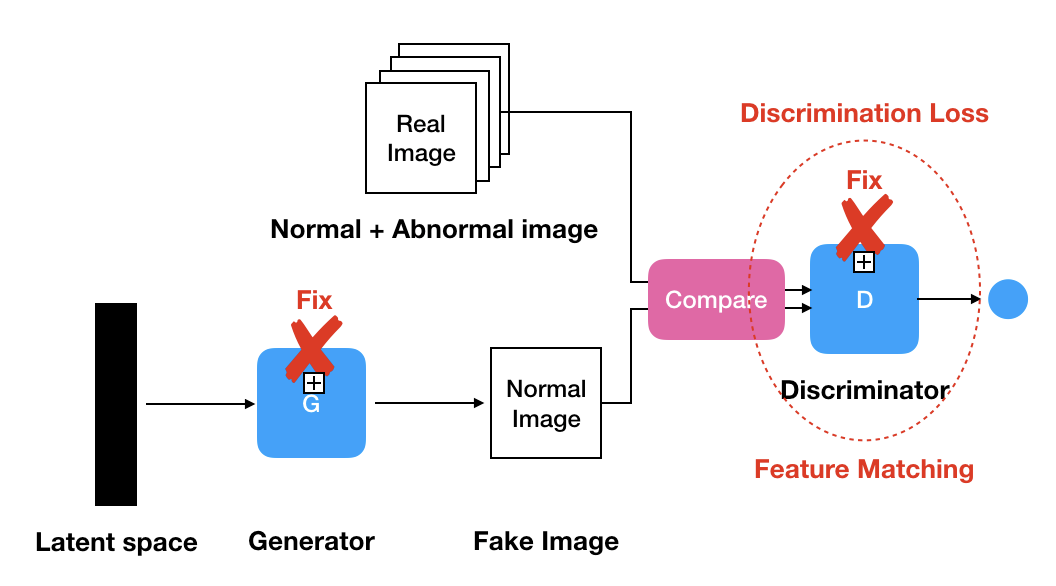 Discriminator의 역할은 True/False를 판별해주는 역할을 갖고 있습니다. 이런 기능을 이용해서 들어오는 입력 데이터들의 확률분포(Probability Distribution)을 파악해서 True/False를 판단해줄 수 있습니다. 즉, Discrimination Loss는 $G(z_r)$의 Manifold 또는 Data Distribution에 잘 Mapping되도록 패널티를 부과하는 Loss 입니다. 다만, 이때 Discriminator의 중간 레이어에서 뽑은 Feture를 이용해서 계산을 하고 있습니다. 그 이유는 논문에서 중간층이 더 많은 표현력을 갖고 있다고 나와있습니다. 이러한 과정을 Feature Mapping이라고 불립니다.
Discriminator의 역할은 True/False를 판별해주는 역할을 갖고 있습니다. 이런 기능을 이용해서 들어오는 입력 데이터들의 확률분포(Probability Distribution)을 파악해서 True/False를 판단해줄 수 있습니다. 즉, Discrimination Loss는 $G(z_r)$의 Manifold 또는 Data Distribution에 잘 Mapping되도록 패널티를 부과하는 Loss 입니다. 다만, 이때 Discriminator의 중간 레이어에서 뽑은 Feture를 이용해서 계산을 하고 있습니다. 그 이유는 논문에서 중간층이 더 많은 표현력을 갖고 있다고 나와있습니다. 이러한 과정을 Feature Mapping이라고 불립니다.
$$
L_D(z_r) = \sum |f(x) - f(G(z_r))|
$$
⎮ Residual + Discrimination Loss
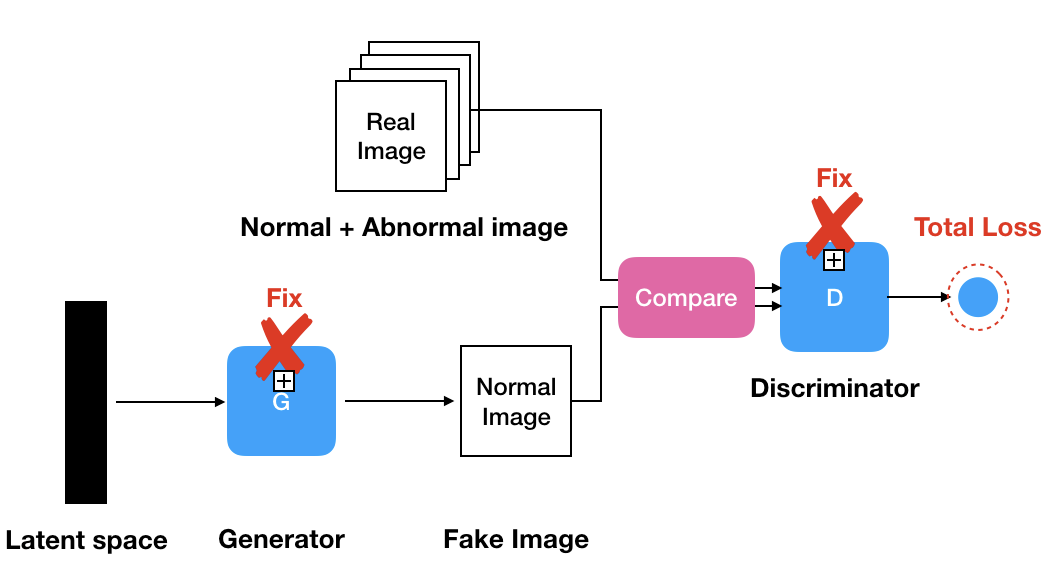
$$
L(z_r) = (1 - \lambda) \cdot L_R(z_r) + \lambda \cdot L_D(z_r)
$$
$z_1$에 대한 L(z_r)를 구하는 과정입니다. 이 과정은 Generatir와 Discriminator의 weight를 Fixed 시켜주고 $L(z_r)$가 최소가 되도록 latent vector를 Gradient Descent 과정을 통해서 조정 시켜줍니다.
따라서 $z_1 \rightarrow z_2 \rightarrow z_3 \rightarrow …. z_r$로 여러번 iteration 시켜주면서 제대로 query image와 $G(z)$와 mapping이 제대로 이루어지는 값을 찾는 과정을 진행합니다. (OCT 데이터셋은 500번 iteration 해주었습니다)
또한 $L(z_r)$를 Anomaly Score로 사용해서 판단의 기준으로 사용하게 됩니다.
Architecture
DCGAN
DCGAN 원 논문에서 사용한 데이터는 RGB(3channels)이였습니다. 그렇지만 OCT 영상 데이터는 gray-scale(1channel)이여서 parameter만 변경을 시켜준 상태로 사용을 했습니다.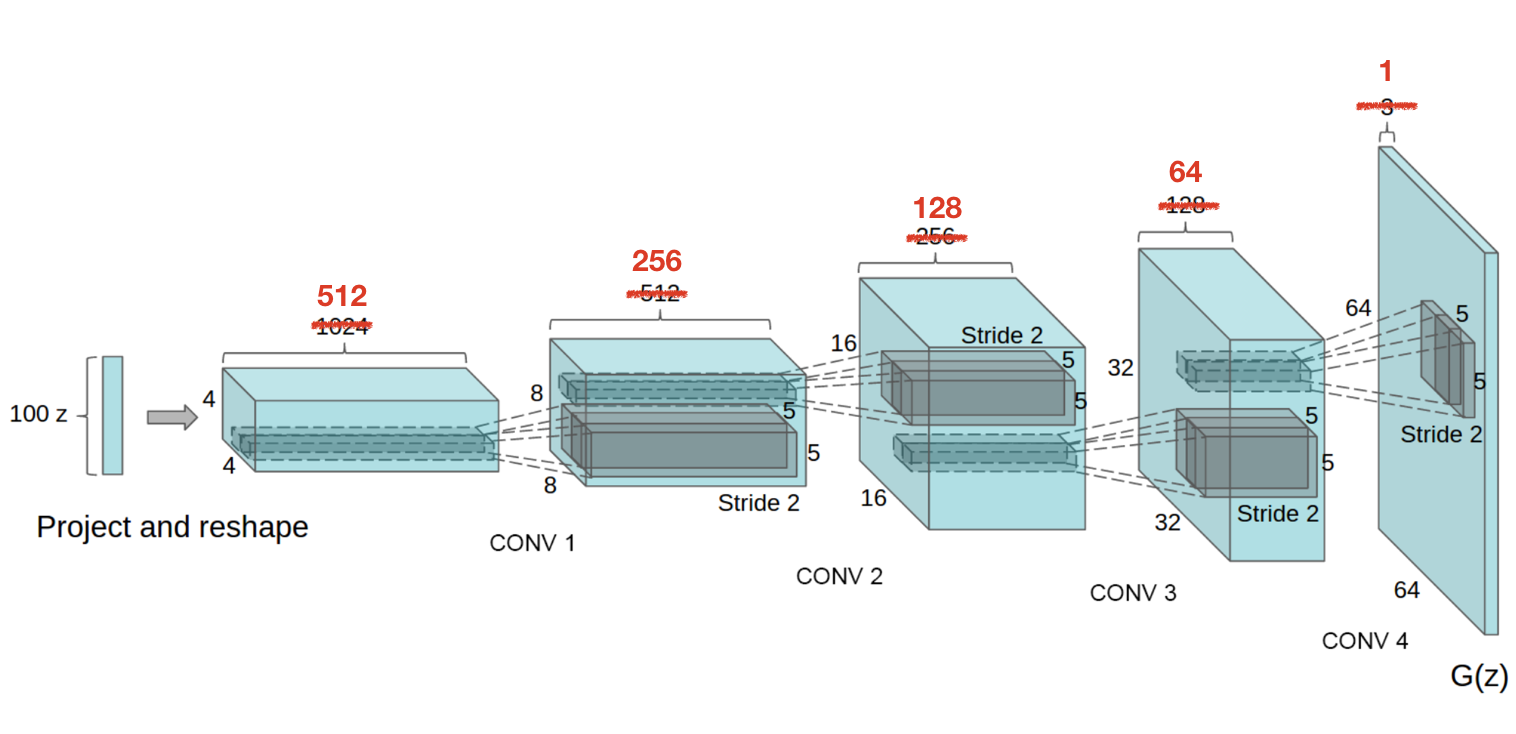
AnoGAN
Conclusion
AnoGAN 전 과정을 요약 해보자면
- Normal Data로만 GAN을 학습 시킵니다. 잘 학습된 GAN은 Normal 이미지만 생성하게 됩니다.
- latent space에서 $z_r$값을 random sampling 해줍니다.
- Sampling해준 $z_r$을 이용해 query data와 비슷하게 생성되는지 $G(z_r)$와 query image와 비교를 합니다. 이 과정은 inference 과정에서 이루어짐니다.
- query image와 $G(z_r)$이 비슷한 Distribution으로 mapping이 되었다면 비정상 query image가 들어왓다고 해도 $G(z_r)$은 정상이지만 query image와 구조적으론 똑같은 이미지로 생성이 될 것 입니다. 이 때 Anomaly Score를 계산해줍니다.